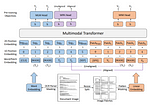
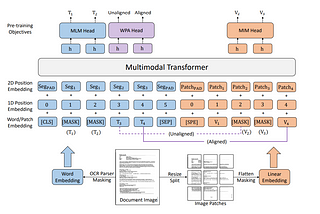
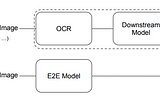
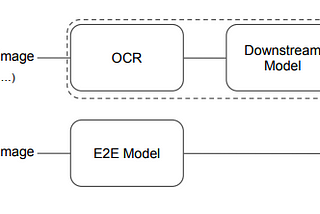
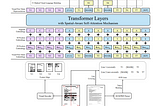
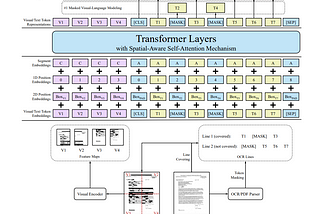
paper summary: “LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking”arxiv: https://arxiv.org/abs/2204.08387Jun 13, 20223Jun 13, 20223
paper review: “Large Language Models are Zero-Shot Reasoners”arxiv: https://arxiv.org/abs/2205.11916May 29, 20222May 29, 20222
paper review: “VOS: LEARNING WHAT YOU DON’T KNOW BY VIRTUAL OUTLIER SYNTHESIS”arxiv: https://arxiv.org/abs/2202.01197Apr 14, 202211Apr 14, 202211
Paper Review: “Donut : Document Understanding Transformer without OCR”arxiv: https://arxiv.org/abs/2111.15664Jan 15, 202220Jan 15, 202220
paper summary: “BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation…arxiv: https://arxiv.org/abs/1910.13461Jan 11, 202271Jan 11, 202271
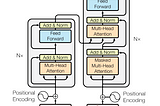
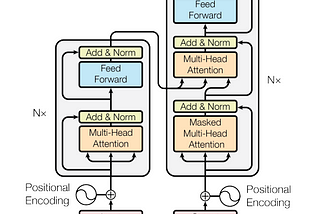
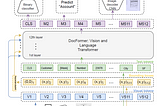
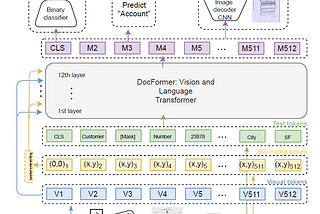
paper review: “DocFormer: End-to-End Transformer for Document Understanding”arxiv: https://arxiv.org/abs/2106.11539Nov 23, 20214Nov 23, 20214
paper summary: “LayoutLMV2: Multi-Modal Pre-training for Visually-Rich Document Understanding”arxiv: https://arxiv.org/abs/2012.14740Nov 19, 2021112Nov 19, 2021112
paper summary: “BROS: A Pre-trained Language Model Focusing on Text and Layout for Better Key…arxiv: https://arxiv.org/abs/2108.04539Nov 10, 20219Nov 10, 20219
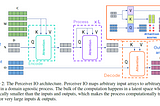
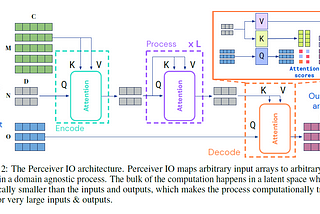
Published inNerd For Techpaper summary “Perceiver IO: A General Architecture for Structured Inputs & Outputs”arxiv: https://arxiv.org/abs/2107.14795Sep 27, 20216Sep 27, 20216
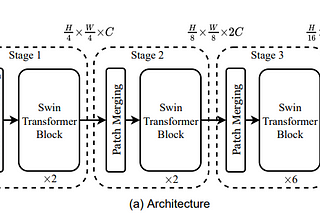
Published inNerd For Techpaper summary: Swin Transformer: Hierarchical Vision Transformer using Shifted Windowsarxiv: https://arxiv.org/abs/2103.14030Sep 10, 202140Sep 10, 202140